Time : assessment period (levels = “t0”, “t1”, “t2”, “t3”, “t6”, “t8”)
age : individual age at each assessment (years)
m_mirwald : calculation of maturity offset according to Mirwald et al. 2002 (Mirwald et al., 2002) (years)
\[\begin{align}
\begin{aligned}
girls: &-9.376 \\
&+ (.0001882 * (stand - sit) * sit) \\
&+ (.0022 * (stand - sit) * age) \\
&+ (.005841 * age * sit) \\
&+ (-.002658 * age * weight) \\
&+ (.07693 * weight / stand * 100) \\
boys: &-9.236 \\
&+ (.0002708 * (stand - sit) * sit) \\
&+ (-.001663 * (stand - sit) * age) \\
&+ (.007216 * age * sit) \\
&+ (.02292 * weight / stand * 100)
\end{aligned}
\end{align}\]
m_moore : calculation of maturity offset according to Moore et al. 2012 (Moore et al., 2015) (years)
ages <-as_tibble(tx) |>select(Child ="id", "gender",starts_with("date"),starts_with(c("t0","t1","t2","t3","t6","t8")) &contains(c("height","weight"))) |>pivot_longer(10:27, names_to =c("Time","Type","Test", "Measure"),names_sep ="_", values_to ="value") |>select(-Test,-Type) |>pivot_wider(names_from = Measure,values_from = value) |>mutate(date =case_when(Time =="t0"~ date.t0, Time =="t1"~ date.t1, Time =="t2"~ date.t2, Time =="t3"~ date.t3, Time =="t6"~ date.t6, Time =="t8"~ date.t8),date = zoo::as.Date(date),age =as.numeric((date - date.of.birth)/365.25),m_mirwald =ifelse(gender=="w",-9.376+ (.0001882* (stand - sit) * sit) + (.0022* (stand - sit) * age) + (.005841* age * sit) + (-.002658* age * weight) + (.07693* weight / stand *100),-9.236+ (.0002708* (stand - sit) * sit) + (-.001663* (stand - sit) * age) + (.007216* age * sit) + (.02292* weight / stand *100)),m_moore =ifelse(gender =="w",-7.709133+ (.0042232* (age * stand)),-8.128741+ (.0070346* (age * sit))),bmi=weight/((stand/100)^2)) |>select(Child, Time, age, m_mirwald, m_moore)save(ages, file="data/ages.rda")
Scores for the 20-m sprint and the star run where transformed from time to completion (s) into average speed (m/s) (Fühner et al., 2021, 2022). Z-scores were based norm values for key age children published in Fühner et al. 2021 (Fühner et al., 2021) for 6 min run, star run, 20 m sprint, standing long jump, and ball push test. As indicated by preliminary EMOTIKON analyses, one leg balance test were log-transformed and then z-transformed across the SMaRTER sample.
Code
data.frame(Test=c("Run (m)","Star_r (m/s)", "S20_r (m/s)", "SLJ (cm)", "BPT (m)", "OLB (s)"),mean=c("1004", "2.05", "4.52", "126", "3.74", "2.08"),sd=c("148", "0.288", "0.413", "19.3", "714", "0.768")) |>flextable() |>autofit() |>align(j=2:3, align ="right") |>add_footer_row(values =c("Run = 6 min run, Star_r = star run, S20_r = 20 m sprint, SLJ = standing long jump, BPT = ball push test, OLB = one leg balance"), colwidths =3)
Table 8.1: EMOTIKON values according to Fühner et al. 2021
Test
mean
sd
Run (m)
1004
148
Star_r (m/s)
2.05
0.288
S20_r (m/s)
4.52
0.413
SLJ (cm)
126
19.3
BPT (m)
3.74
714
OLB (s)
2.08
0.768
Run = 6 min run, Star_r = star run, S20_r = 20 m sprint, SLJ = standing long jump, BPT = ball push test, OLB = one leg balance
Code
emo <-as_tibble(tx) |>select(Child ="id",starts_with(c("t0","t1","t2","t3","t6","t8")) &contains("motor_emo")) |>pivot_longer(2:37, names_to =c("Time","type","domain", "Test"),names_sep ="_", values_to ="Score") |>select(-domain, -type) |>mutate(across(where(is.character), as.factor),Test =fct_recode(Test, Run ="endurance", Star_r ="star", S20_r ="sprint",SLJ ="jump", BPT ="toss", OLB_l ="oneleg"),Test =fct_relevel(Test, "Run", "Star_r", "S20_r", "SLJ", "BPT", "OLB_l"),Score =case_when(Test =="Star_r"~50.912/Score, Test =="S20_r"~20./Score, Test =="OLB_l"~log(Score),TRUE~ Score),zScore =case_when(Test =="Run"~ (Score -1004)/148, Test =="Star_r"~ (Score -2.05)/.288, Test =="S20_r"~ (Score -4.52)/.413, Test =="SLJ"~ (Score -126)/19.3, Test =="BPT"~ (Score -3.74)/.714, Test =="OLB_l"~ (Score -2.08)/.768))save(emo, file="data/emo.rda")
8.1.5 “cog”
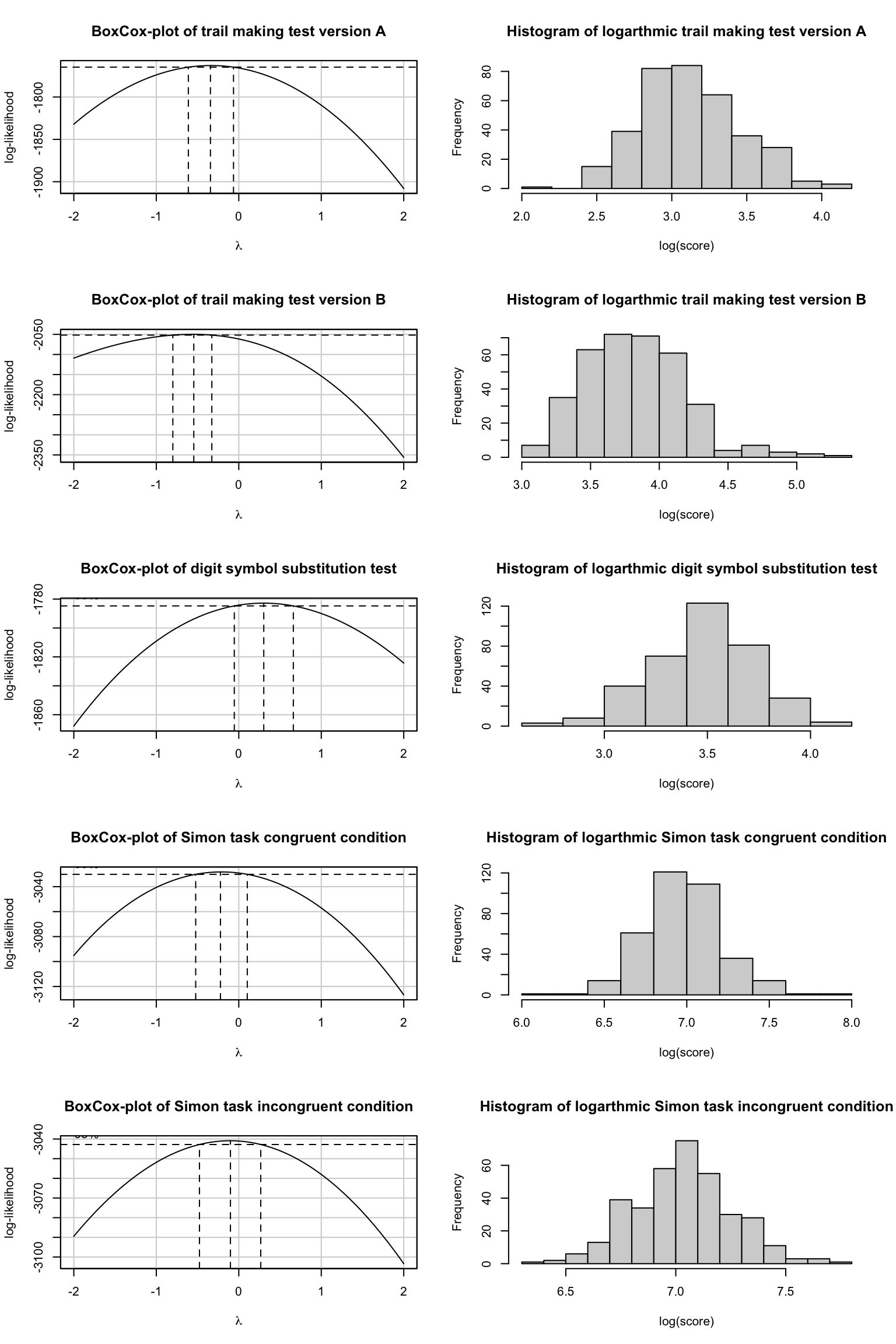
A Box-Cox distribution analysis (Box & Cox, 1964) suggested logarithmic transformations for all executive function tests to obtain normally distributed model residuals (see Figure 8.1). Accordingly, lag transformed means and standard deviations were used for z-transformation (see Table 8.2). Further, the z-transformed scores for the trail making test and Simon task were reversed, so positive improvements of z-values indicate and improvement in time to completion or reaction time.
Code
data.frame(Test=c("TMTa (s)","TMTb (s)","DSST (n)","SC (ms)","SI (ms)"),mean=c("3.12","3.83","3.47","6.97","7.03"),sd=c("0.328","0.370","0.244","0.228","0.223")) |>flextable() |>autofit() |>align(j=2:3, align ="right") |>add_footer_row(values =c("TMTa = trail making test verion A, TMTb = trail making test version B, DSST = digit symbol substitution test, SC = Simon task congruent condition, SI = Simon task incongruent condition"), colwidths =3)
Table 8.2: Mean and standard deviation of executive function log-scores
Test
mean
sd
TMTa (s)
3.12
0.328
TMTb (s)
3.83
0.370
DSST (n)
3.47
0.244
SC (ms)
6.97
0.228
SI (ms)
7.03
0.223
TMTa = trail making test verion A, TMTb = trail making test version B, DSST = digit symbol substitution test, SC = Simon task congruent condition, SI = Simon task incongruent condition
Code
cog <-as_tibble(tx) |>select(Child ="id",contains("dsst"),contains("tmt") &ends_with("Time"),contains("simon_m.rt")) |>mutate(t0_cog_dsst_dsst.score=t0_cog_dsst_num-t0_cog_dsst_err,t1_cog_dsst_dsst.score=t1_cog_dsst_num-t1_cog_dsst_err,t2_cog_dsst_dsst.score=t2_cog_dsst_num-t2_cog_dsst_err,t3_cog_dsst_dsst.score=t3_cog_dsst_num-t3_cog_dsst_err,t6_cog_dsst_dsst.score=t6_cog_dsst_num-t6_cog_dsst_err,t8_cog_dsst_dsst.score=t8_cog_dsst_num-t8_cog_dsst_err) |>select(-contains("num")&-contains("err")) |>pivot_longer(2:31, names_to =c("Time","type","domain", "Test"),names_sep ="_", values_to ="Score") |>select(-domain, -type) |>mutate(across(where(is.character), as.factor),Test =fct_recode(Test, TMTa ="a.time", TMTb ="b.time", DSST ="dsst.score",SC ="m.rt.con", SI ="m.rt.incon"),Test =fct_relevel(Test, "TMTa", "TMTb", "DSST", "SC", "SI"),zScore =case_when(Test =="TMTa"~-(log(Score) -3.12)/.328, Test =="TMTb"~-(log(Score) -3.83)/.370, Test =="DSST"~ (log(Score) -3.47)/.244, Test =="SC"~-(log(Score) -6.97)/.228, Test =="SI"~-(log(Score) -7.03)/.223))save(cog, file="data/cog.rda")par(mfrow=c(5,2))car::boxCox(lm(Score ~1, data = cog[which(cog$Test=="TMTa"),]), main ="BoxCox-plot of trail making test version A") hist(log(cog[which(cog$Test=="TMTa"),]$Score), main ="Histogram of logarthmic trail making test version A", xlab ="log(score)")car::boxCox(lm(Score ~1, data = cog[which(cog$Test=="TMTb"),]), main ="BoxCox-plot of trail making test version B") hist(log(cog[which(cog$Test=="TMTb"),]$Score), main ="Histogram of logarthmic trail making test version B", xlab ="log(score)")car::boxCox(lm(Score ~1, data = cog[which(cog$Test=="DSST"),]), main ="BoxCox-plot of digit symbol substitution test") hist(log(cog[which(cog$Test=="DSST"),]$Score), main ="Histogram of logarthmic digit symbol substitution test", xlab ="log(score)")car::boxCox(lm(Score ~1, data = cog[which(cog$Test=="SC"),]), main ="BoxCox-plot of Simon task congruent condition") hist(log(cog[which(cog$Test=="SC"),]$Score), main ="Histogram of logarthmic Simon task congruent condition", xlab ="log(score)")car::boxCox(lm(Score ~1, data = cog[which(cog$Test=="SI"),]), main ="BoxCox-plot of Simon task incongruent condition") hist(log(cog[which(cog$Test=="SI"),]$Score), main ="Histogram of logarthmic Simon task incongruent condition", xlab ="log(score)")
Figure 8.1: Box-Cox distribution and histograms of executive function tests
8.2 Supplementary Material Chapter 2
8.2.1 Body mass index analysis for t1 and t3 populations
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(where(is.numeric), round, 3)`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))
LRT 1 of fixed effects in INT M1 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m1.1_emo
6
1,227.027
1,253.005
-607.513
1,215.027
m1.2_emo
18
1,232.915
1,310.850
-598.457
1,196.915
18.112
12
0.112
m1.3_emo_abp
21
1,228.853
1,319.777
-593.427
1,186.853
10.061
3
0.018
*
m1.4_emo_all
22
1,230.662
1,325.916
-593.331
1,186.662
0.191
1
0.662
m1.1_emo
6
1,227.027
1,253.005
-607.513
1,215.027
m1.2_emo
18
1,232.915
1,310.850
-598.457
1,196.915
18.112
12
0.112
m1.3_emo_gbp
21
1,229.324
1,320.248
-593.662
1,187.324
9.591
3
0.022
*
m1.4_emo_all
22
1,230.662
1,325.916
-593.331
1,186.662
0.661
1
0.416
m1.1_emo
6
1,227.027
1,253.005
-607.513
1,215.027
m1.2_emo
18
1,232.915
1,310.850
-598.457
1,196.915
18.112
12
0.112
m1.3_emo_gap
21
1,234.319
1,325.243
-596.159
1,192.319
4.596
3
0.204
m1.4_emo_all
22
1,230.662
1,325.916
-593.331
1,186.662
5.657
1
0.017
*
m1.1_emo
6
1,227.027
1,253.005
-607.513
1,215.027
m1.2_emo
18
1,232.915
1,310.850
-598.457
1,196.915
18.112
12
0.112
m1.3_emo_gab
21
1,229.686
1,320.610
-593.843
1,187.686
9.229
3
0.026
*
m1.4_emo_all
22
1,230.662
1,325.916
-593.331
1,186.662
1.023
1
0.312
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that body mass index (BMI) improves the model’s fit, while age, gender, and Berlin proximity can be dropped.
m1.5_emo_bmi <-update(m1.1_emo, . ~ . - Test + Test/(Group * Time) + bmi_c)m1.6_emo_bmi <-update(m1.1_emo, . ~ . - Test + Test/(Group * Time + bmi_c))m1.7_emo_bmi <-update(m1.1_emo, . ~ . - Test + Test/((Group + Time + bmi_c)^2))
LRT 2 of fixed effects in INT M1 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m1.1_emo
6
1,227.027
1,253.005
-607.513
1,215.027
m1.2_emo
18
1,232.915
1,310.850
-598.457
1,196.915
18.112
12
0.112
m1.5_emo_bmi
19
1,226.565
1,308.830
-594.282
1,188.565
8.350
1
0.004
**
m1.6_emo_bmi
22
1,185.591
1,280.845
-570.796
1,141.591
46.973
3
0.000
***
m1.7_emo_bmi
30
1,195.350
1,325.242
-567.675
1,135.350
6.241
8
0.620
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT further showed that including BMI nested within Test without interactions improves the models fit. Accordingly, m1.6_emo_bmi was reported in Section 3.3.1.1.
8.3.1.2 Means and standard deviations of model variables
`summarise()` has grouped output by 'Time'. You can override using the
`.groups` argument.
Means and standard deviation of the model variables used in INT M1
physical fitness
Time
t0
t1
Group
CON
INT
CON
INT
gender [girl/boy]
16/15
16/25
16/14
14/25
Berlin proximity [close/far]
15/16
0/41
15/15
0/39
BMI [kg/m²]
18.4±4.7
19.1±5
18.5±4.8
19.5±4.9
age [years]
9.1±0.5
9.2±0.6
9.4±0.5
9.5±0.6
20 m sprint [m/s]
4.1±0.4
4.1±0.3
4.1±0.5
4.1±0.3
standing long jump [cm]
107.1±23.9
106.4±13.6
110.2±24.7
106.8±14.2
star run [m/s]
1.8±0.2
1.8±0.2
1.9±0.2
1.8±0.2
6 min run [m]
876.8±129.9
834.1±119.3
896.1±144.3
863.5±125.1
CON = control condition; INT = intervention condition; BMI = body mass index
LRT 1 of fixed effects in INT M1 - executive function
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m1.1_cog
7
1,776.276
1,808.183
-881.138
1,762.276
m1.2_cog
22
1,765.195
1,865.475
-860.597
1,721.195
41.081
15
0.000
***
m1.3_cog_abp
25
1,769.455
1,883.410
-859.727
1,719.455
1.740
3
0.628
m1.4_cog_all
26
1,764.845
1,883.359
-856.423
1,712.845
6.609
1
0.010
*
m1.1_cog
7
1,776.276
1,808.183
-881.138
1,762.276
m1.2_cog
22
1,765.195
1,865.475
-860.597
1,721.195
41.081
15
0.000
***
m1.3_cog_gbp
25
1,762.846
1,876.801
-856.423
1,712.846
8.349
3
0.039
*
m1.4_cog_all
26
1,764.845
1,883.359
-856.423
1,712.845
0.001
1
0.982
m1.1_cog
7
1,776.276
1,808.183
-881.138
1,762.276
m1.2_cog
22
1,765.195
1,865.475
-860.597
1,721.195
41.081
15
0.000
***
m1.3_cog_gap
25
1,763.515
1,877.470
-856.758
1,713.515
7.679
3
0.053
m1.4_cog_all
26
1,764.845
1,883.359
-856.423
1,712.845
0.670
1
0.413
m1.1_cog
7
1,776.276
1,808.183
-881.138
1,762.276
m1.2_cog
22
1,765.195
1,865.475
-860.597
1,721.195
41.081
15
0.000
***
m1.3_cog_gab
25
1,763.611
1,877.566
-856.806
1,713.611
7.583
3
0.055
m1.4_cog_all
26
1,764.845
1,883.359
-856.423
1,712.845
0.766
1
0.381
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that gender improves the model’s fit, while age, BMI, and Berlin proximity can be dropped.
m1.5_cog_gender <-update(m1.1_cog, . ~ . - Test + Test/(Group * Time) + gender)m1.6_cog_gender <-update(m1.1_cog, . ~ . - Test + Test/(Group * Time + gender))m1.7_cog_gender <-update(m1.1_cog, . ~ . - Test + Test/((Group + Time + gender)^2))
LRT 2 of fixed effects in INT M1 - executive function
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m1.1_cog
7
1,776.276
1,808.183
-881.138
1,762.276
m1.2_cog
22
1,765.195
1,865.475
-860.597
1,721.195
41.081
15
0.000
***
m1.5_cog_gender
23
1,761.022
1,865.861
-857.511
1,715.022
6.172
1
0.013
*
m1.6_cog_gender
27
1,761.152
1,884.223
-853.576
1,707.152
7.871
4
0.096
m1.7_cog_gender
37
1,772.997
1,941.650
-849.498
1,698.997
8.155
10
0.614
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT further showed that gender added as a fixed factor not nested within Test improves the models fit. Accordingly, m1.5_cog_bmi was reported in Section 3.3.2.1.
8.3.2.2 Means and standard deviations of model variables
`summarise()` has grouped output by 'Time'. You can override using the
`.groups` argument.
Means and standard deviation of the model variables used in INT M1
executive function
Time
t0
t1
Group
CON
INT
CON
INT
gender [girl/boy]
16/15
16/25
16/14
14/25
Berlin proximity [close/far]
15/16
0/41
15/15
0/39
BMI [kg/m²]
18.4±4.7
19.1±5
18.5±4.8
19.5±4.9
age [years]
9.1±0.5
9.2±0.6
9.4±0.5
9.5±0.6
TMT version A [s]
30.3±8.3
31.2±11.1
26.5±8.4
25.1±7.4
TMT version B [s]
64.7±34.4
59.3±19.6
58.6±22.8
53.1±20.3
DSST [n]
28.5±5.2
27.1±5.3
30.4±6.5
30.6±6.2
SC [ms]
1198.1±202.5
1275.3±340.3
1191.3±273.8
1185.2±283.6
SI [ms]
1277.7±217.5
1335.1±279.1
1205.7±190.6
1244.9±301.8
CON = control condition; INT = intervention condition; TMT = trail making test; DSST = digit symbol substitution test; SC = Simon task congruent condition; Simon task incongruent condition; BMI = body mass index
8.3.3 INT M2: physical fitness
8.3.3.1 Model fitting
Code
data_m2 <-left_join(info, anthro) |>left_join(ages) |>select(Child, bp, Group, gender, Time, bmi, age) |>filter(!(Child %in%c("SMART01", "SMART06", "SMART12", "SMART19", "SMART23", "SMART39", "SMART58", "SMART63", "SMART68", "SMART75" )), Time %in%c("t0","t1","t2","t3"))|>mutate(Group_pooled =case_when(Group=="INT-CON"& Time %in%c("t0", "t1") ~"INT", Group=="INT-CON"& Time %in%c("t2", "t3") ~"CON", Group=="CON-INT"& Time %in%c("t0", "t1") ~"CON", Group=="CON-INT"& Time %in%c("t2", "t3") ~"INT"),Time_pooled =case_when(Time %in%c("t0", "t2") ~"pre", Time %in%c("t1", "t3") ~"post"),Time_pooled=factor(Time_pooled, levels =c("pre","post")),across(where(is.character), as.factor)) |>arrange(Child, Time) |>fill(bmi)
Joining with `by = join_by(Child, Time)`
Joining with `by = join_by(Child, Time)`
LRT 1 of fixed effects in INT M2 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m2.1_emo
6
2,176.077
2,205.636
-1,082.038
2,164.077
m2.2_emo
18
2,176.732
2,265.411
-1,070.366
2,140.732
23.344
12
0.025
*
m2.3_emo_abp
21
2,168.538
2,271.996
-1,063.269
2,126.538
14.194
3
0.003
**
m2.4_emo_all
22
2,169.783
2,278.167
-1,062.891
2,125.783
0.756
1
0.385
m2.1_emo
6
2,176.077
2,205.636
-1,082.038
2,164.077
m2.2_emo
18
2,176.732
2,265.411
-1,070.366
2,140.732
23.344
12
0.025
*
m2.3_emo_gbp
21
2,171.247
2,274.705
-1,064.623
2,129.247
11.486
3
0.009
**
m2.4_emo_all
22
2,169.783
2,278.167
-1,062.891
2,125.783
3.464
1
0.063
m2.1_emo
6
2,176.077
2,205.636
-1,082.038
2,164.077
m2.2_emo
18
2,176.732
2,265.411
-1,070.366
2,140.732
23.344
12
0.025
*
m2.3_emo_gap
21
2,175.276
2,278.734
-1,066.638
2,133.276
7.456
3
0.059
m2.4_emo_all
22
2,169.783
2,278.167
-1,062.891
2,125.783
7.494
1
0.006
**
m2.1_emo
6
2,176.077
2,205.636
-1,082.038
2,164.077
m2.2_emo
18
2,176.732
2,265.411
-1,070.366
2,140.732
23.344
12
0.025
*
m2.3_emo_gab
21
2,170.199
2,273.657
-1,064.100
2,128.199
12.533
3
0.006
**
m2.4_emo_all
22
2,169.783
2,278.167
-1,062.891
2,125.783
2.417
1
0.120
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that BMI improves the model’s fit, while age, gender, and Berlin proximity can be dropped.
LRT 2 of fixed effects in INT M2 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m2.1_emo
6
2,176.077
2,205.636
-1,082.038
2,164.077
m2.2_emo
18
2,176.732
2,265.411
-1,070.366
2,140.732
23.344
12
0.025
*
m2.5_emo_bmi
19
2,170.194
2,263.799
-1,066.097
2,132.194
8.538
1
0.003
**
m2.6_emo_bmi
22
2,113.439
2,221.824
-1,034.720
2,069.439
62.755
3
0.000
***
m2.7_emo_bmi
30
2,123.595
2,271.392
-1,031.797
2,063.595
5.845
8
0.665
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT further showed that BMI added as a fixed factor nested within Test without interactions improves the models fit. Accordingly, m2.6_emo_bmi was reported in Section 3.4.1.1.
8.3.3.2 Means and standard deviations of model variables
`summarise()` has grouped output by 'Time_pooled'. You can override using the
`.groups` argument.
Means and standard deviation of the model variables used in INT M2
physical fitness
Time [pooled]
pre
post
Group [pooled]
CON
INT
CON
INT
gender [girl/boy]
28/38
27/38
28/36
26/36
Berlin proximity [close/far]
14/52
14/51
14/50
13/49
BMI [kg/m²]
19.1±4.8
19.1±4.9
19.3±5.1
19.8±4.9
age [years]
9.4±0.6
9.4±0.6
9.8±0.7
9.7±0.6
20 m sprint [m/s]
4.1±0.4
4.1±0.4
4.1±0.4
4.1±0.4
standing long jump [cm]
108.4±20.6
107.6±18.5
112.2±20.7
108.3±19.5
star run [m/s]
1.8±0.2
1.8±0.2
1.9±0.2
1.9±0.2
6 min run [m]
850.4±127
853.6±144
880.1±140
872.7±132.4
CON = control condition; INT = intervention condition; BMI = body mass index
LRT 1 of fixed effects in INT M2 - executive function
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m2.1_cog
7
3,279.784
3,315.915
-1,632.892
3,265.784
m2.2_cog
22
3,246.800
3,360.356
-1,601.400
3,202.800
62.984
15
0.000
***
m2.3_cog_abp
25
3,105.015
3,234.055
-1,527.507
3,055.015
147.785
3
0.000
***
m2.4_cog_all
26
3,106.509
3,240.712
-1,527.255
3,054.509
0.505
1
0.477
m2.1_cog
7
3,279.784
3,315.915
-1,632.892
3,265.784
m2.2_cog
22
3,246.800
3,360.356
-1,601.400
3,202.800
62.984
15
0.000
***
m2.3_cog_gbp
25
3,236.158
3,365.198
-1,593.079
3,186.158
16.642
3
0.001
***
m2.4_cog_all
26
3,106.509
3,240.712
-1,527.255
3,054.509
131.648
1
0.000
***
m2.1_cog
7
3,279.784
3,315.915
-1,632.892
3,265.784
m2.2_cog
22
3,246.800
3,360.356
-1,601.400
3,202.800
62.984
15
0.000
***
m2.3_cog_gap
25
3,106.976
3,236.016
-1,528.488
3,056.976
145.824
3
0.000
***
m2.4_cog_all
26
3,106.509
3,240.712
-1,527.255
3,054.509
2.467
1
0.116
m2.1_cog
7
3,279.784
3,315.915
-1,632.892
3,265.784
m2.2_cog
22
3,246.800
3,360.356
-1,601.400
3,202.800
62.984
15
0.000
***
m2.3_cog_gab
25
3,104.689
3,233.730
-1,527.345
3,054.689
148.111
3
0.000
***
m2.4_cog_all
26
3,106.509
3,240.712
-1,527.255
3,054.509
0.180
1
0.671
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that age improves the model’s fit, while BMI, gender, and Berlin proximity can be dropped.
LRT 2 of fixed effects in INT M2 - executive function
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m2.1_cog
7
3,279.784
3,315.915
-1,632.892
3,265.784
m2.2_cog
22
3,246.800
3,360.356
-1,601.400
3,202.800
62.984
15
0.000
***
m2.5_cog_gender
23
3,103.466
3,222.184
-1,528.733
3,057.466
145.334
1
0.000
***
m2.6_cog_gender
27
3,106.360
3,245.724
-1,526.180
3,052.360
5.107
4
0.277
m2.7_cog_gender
37
3,114.710
3,305.690
-1,520.355
3,040.710
11.650
10
0.309
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT further showed that age added as a fixed factor not nested within Test improves the models fit. Accordingly, m2.5_cog_bmi was reported in Section 3.4.2.1.
8.3.4.2 Means and standard deviations of model variables
`summarise()` has grouped output by 'Time_pooled'. You can override using the
`.groups` argument.
Means and standard deviation of the model variables used in INT M2
executive function
Time [pooled]
pre
post
Group [pooled]
CON
INT
CON
INT
gender [girl/boy]
28/38
27/38
28/37
26/37
Berlin proximity [close/far]
14/52
14/51
14/51
14/49
BMI [kg/m²]
19.1±4.8
19.1±4.9
19.3±5
19.7±4.9
age [years]
9.4±0.6
9.4±0.6
9.8±0.7
9.7±0.6
TMT version A [s]
25.8±8.3
27.9±10.5
23.9±7.3
23.6±7.4
TMT version B [s]
55.4±27.5
59.1±24.5
46.7±19.1
47.8±17.5
DSST [n]
31.4±6.6
29.4±6.9
33.3±6.9
32.3±6.8
SC [ms]
1133.1±224.9
1168.9±319
1104.6±225.6
1106.5±273.6
SI [ms]
1209.4±236.8
1249.8±270
1133±187.7
1176.2±303.1
CON = control condition; INT = intervention condition; TMT = trail making test; DSST = digit symbol substitution test; SC = Simon task congruent condition; Simon task incongruent condition; BMI = body mass index
LRT 1 of fixed effects in INT M3 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.3_emo_abp
53
1,862.963
2,113.580
-878.482
1,756.963
17.011
3
0.001
***
m3.4_emo_all
54
1,864.902
2,120.248
-878.451
1,756.902
0.061
1
0.804
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.3_emo_gbp
53
1,862.951
2,113.568
-878.475
1,756.951
17.023
3
0.001
***
m3.4_emo_all
54
1,864.902
2,120.248
-878.451
1,756.902
0.049
1
0.824
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.3_emo_gap
53
1,870.924
2,121.541
-882.462
1,764.924
9.050
3
0.029
*
m3.4_emo_all
54
1,864.902
2,120.248
-878.451
1,756.902
8.022
1
0.005
**
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.3_emo_gab
53
1,867.524
2,118.142
-880.762
1,761.524
12.450
3
0.006
**
m3.4_emo_all
54
1,864.902
2,120.248
-878.451
1,756.902
4.623
1
0.032
*
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that BMI and Berlin proximity improves the model’s fit, while age and gender can be dropped.
m3.5_emo_bmi <-update(m3.1_emo, . ~ . - Test + Test/(Group * Time) + bmi_c)m3.6_emo_bmi <-update(m3.1_emo, . ~ . - Test + Test/(Group * Time + bmi_c))m3.7_emo_bmi <-update(m3.1_emo, . ~ . - Test + Test/((Group + Time + bmi_c)^2))m3.5_emo_bp <-update(m3.1_emo, . ~ . - Test + Test/(Group * Time) + bp)m3.6_emo_bp <-update(m3.1_emo, . ~ . - Test + Test/(Group * Time + bp))m3.7_emo_bp <-update(m3.1_emo, . ~ . - Test + Test/((Group + Time + bp)^2))
fixed-effect model matrix is rank deficient so dropping 4 columns / coefficients
LRT 2 of fixed effects in INT M3 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.5_emo_bmi
51
1,863.558
2,104.718
-880.779
1,761.558
12.416
1
0.000
***
m3.6_emo_bmi
54
1,795.105
2,050.451
-843.553
1,687.105
74.453
3
0.000
***
m3.7_emo_bmi
78
1,827.327
2,196.160
-835.664
1,671.327
15.778
24
0.896
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.5_emo_bp
51
1,867.127
2,108.287
-882.564
1,765.127
8.847
1
0.003
**
m3.6_emo_bp
54
1,840.301
2,095.647
-866.151
1,732.301
32.826
3
0.000
***
m3.7_emo_bp
74
1,855.488
2,205.406
-853.744
1,707.488
24.813
20
0.209
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that BMI and Berlin proximity added in the fixed structure nested within Test improves the model’s fit.
Code
m3.6_emo_bmibp <-update(m3.1_emo, . ~ . - Test + Test/(Group * Time + bmi_c + bp))m3.6_emo_bmibp2 <-update(m3.1_emo, . ~ . - Test + Test/(Group * Time + bmi_c * bp))
LRT 3 of fixed effects in INT M3 - physical fitness
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.6_emo_bmi
54
1,795.105
2,050.451
-843.553
1,687.105
86.869
4
0.000
***
m3.6_emo_bmibp
58
1,788.050
2,062.310
-836.025
1,672.050
15.055
4
0.005
**
m3.6_emo_bmibp2
62
1,789.523
2,082.698
-832.762
1,665.523
6.527
4
0.163
m3.1_emo
6
1,918.185
1,946.556
-953.092
1,906.185
m3.2_emo
50
1,873.974
2,110.405
-886.987
1,773.974
132.211
44
0.000
***
m3.6_emo_bp
54
1,840.301
2,095.647
-866.151
1,732.301
41.673
4
0.000
***
m3.6_emo_bmibp
58
1,788.050
2,062.310
-836.025
1,672.050
60.251
4
0.000
***
m3.6_emo_bmibp2
62
1,789.523
2,082.698
-832.762
1,665.523
6.527
4
0.163
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT further indicated that BMI and Berlin proximity both added to the fixed structure nested within Test without interactions improves the model’s fit. Accordingly, m3.6_emo_bmibp was reported in Section 3.5.1.1.
8.3.5.2 Means and standard deviations of model variables
`summarise()` has grouped output by 'Time'. You can override using the
`.groups` argument.
Means and standard deviation of the model variables used in INT M3
physical fitness
Time
t0
t1
t2
t3
t6
t8
Group
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
gender [girl/boy]
9/9
7/12
9/8
6/12
9/9
7/12
9/7
7/12
7/7
7/10
9/8
7/12
Berlin proximity [close/far]
8/10
0/19
8/9
0/18
8/10
0/19
7/9
0/19
8/6
0/17
7/10
0/19
BMI [kg/m²]
19±5
20±6
19±5
21±6
19±5
20±6
20±6
21±6
19±6
20±5
21±6
22±7
age [years]
9±0.4
9.2±0.5
9.3±0.4
9.5±0.5
9.5±0.4
9.7±0.5
9.9±0.4
10.1±0.5
10.5±0.4
10.6±0.4
11.5±0.4
11.7±0.5
20 m sprint [m/s]
4.1±0.4
4±0.4
4.1±0.5
4±0.4
4.1±0.3
4.2±0.3
4±0.4
4.1±0.3
4.2±0.4
4.3±0.3
4.3±0.4
4.4±0.5
standing long jump [cm]
111±21
107±14
112±24
106±16
109±18
107±16
109±20
116±18
114±29
120±18
122±26
126±16
star run [m/s]
1.8±0.2
1.7±0.2
1.9±0.2
1.8±0.2
1.8±0.2
1.8±0.2
1.9±0.3
1.9±0.2
2±0.2
2±0.2
2±0.2
2±0.3
6 min run [m]
879±138
794±146
865±133
837±156
854±169
791±103
856±137
837±169
881±196
835±110
825±185
860±174
CON = control condition; INT = intervention condition; BMI = body mass index
LRT 1 of fixed effects in INT M3 - executive function
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m3.1_cog
7
2,832.854
2,867.629
-1,409.427
2,818.854
m3.2_cog
62
2,451.983
2,759.994
-1,163.992
2,327.983
490.870
55
0.000
***
m3.3_cog_abp
65
2,455.093
2,778.007
-1,162.547
2,325.093
2.890
3
0.409
m3.4_cog_all
66
2,454.411
2,782.293
-1,161.206
2,322.411
2.682
1
0.102
m3.1_cog
7
2,832.854
2,867.629
-1,409.427
2,818.854
m3.2_cog
62
2,451.983
2,759.994
-1,163.992
2,327.983
490.870
55
0.000
***
m3.3_cog_gbp
65
2,452.707
2,775.621
-1,161.354
2,322.707
5.276
3
0.153
m3.4_cog_all
66
2,454.411
2,782.293
-1,161.206
2,322.411
0.296
1
0.587
m3.1_cog
7
2,832.854
2,867.629
-1,409.427
2,818.854
m3.2_cog
62
2,451.983
2,759.994
-1,163.992
2,327.983
490.870
55
0.000
***
m3.3_cog_gap
65
2,454.039
2,776.953
-1,162.020
2,324.039
3.944
3
0.268
m3.4_cog_all
66
2,454.411
2,782.293
-1,161.206
2,322.411
1.628
1
0.202
m3.1_cog
7
2,832.854
2,867.629
-1,409.427
2,818.854
m3.2_cog
62
2,451.983
2,759.994
-1,163.992
2,327.983
490.870
55
0.000
***
m3.3_cog_gab
65
2,452.597
2,775.511
-1,161.299
2,322.597
5.386
3
0.146
m3.4_cog_all
66
2,454.411
2,782.293
-1,161.206
2,322.411
0.186
1
0.666
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT indicated that including BMI, Berlin proximity, age, and gender in the fixed factors do not improve the model’s fit. Accordingly, all covariates were dropped and m3.2_cog was reported in Section 3.5.2.1.
8.3.6.2 Means and standard deviations of model variables
`summarise()` has grouped output by 'Time'. You can override using the
`.groups` argument.
Means and standard deviation of the model variables used in INT M3
executive function
Time
t0
t1
t2
t3
t6
t8
Group
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
CON-INT
INT-CON
gender [girl/boy]
9/9
7/12
9/8
6/12
9/9
7/12
9/8
7/12
7/7
7/10
9/9
7/12
Berlin proximity [close/far]
8/10
0/19
8/9
0/18
8/10
0/19
8/9
0/19
8/6
0/17
8/10
0/19
BMI [kg/m²]
19±5
20±6
19±5
21±6
19±5
20±6
20±6
21±6
19±6
20±5
21±6
22±7
age [years]
9±0.4
9.2±0.5
9.3±0.4
9.5±0.5
9.5±0.4
9.7±0.5
9.9±0.4
10.1±0.5
10.5±0.4
10.6±0.4
11.5±0.4
11.7±0.5
TMT version A [s]
28.8±8.6
31.1±11.2
24.5±7.3
24.7±7
22.3±6.7
22.7±7.6
22.3±7.7
23±8.1
19.8±4.9
19.4±5.9
15.5±3.9
18.3±4.4
TMT version B [s]
57.1±18.9
60.5±18.9
54.6±28
52.5±24.9
57.9±36.3
43.4±12.9
39.9±9.2
39.3±8.1
37.8±11.3
40.4±12.1
33.6±9.9
34.4±9
DSST [n]
29.9±5.9
27.1±5.9
31.5±6.8
29.7±6.3
33.4±8.1
33.7±7.7
36.2±7.8
35.3±7
37.9±6.3
35.4±9.1
45.2±8
40.7±7
SC [ms]
1157±200
1286±412
1139±223
1170±300
1026±250
1070±259
943±156
1056±174
985±203
992±180
845±97
869±188
SI [ms]
1246±227
1335±283
1155±152
1232±296
1120±227
1158±272
1028±176
1112±199
1067±218
1089±273
888±133
903±184
CON = control condition; INT = intervention condition; TMT = trail making test; DSST = digit symbol substitution test; SC = Simon task congruent condition; Simon task incongruent condition; BMI = body mass index
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
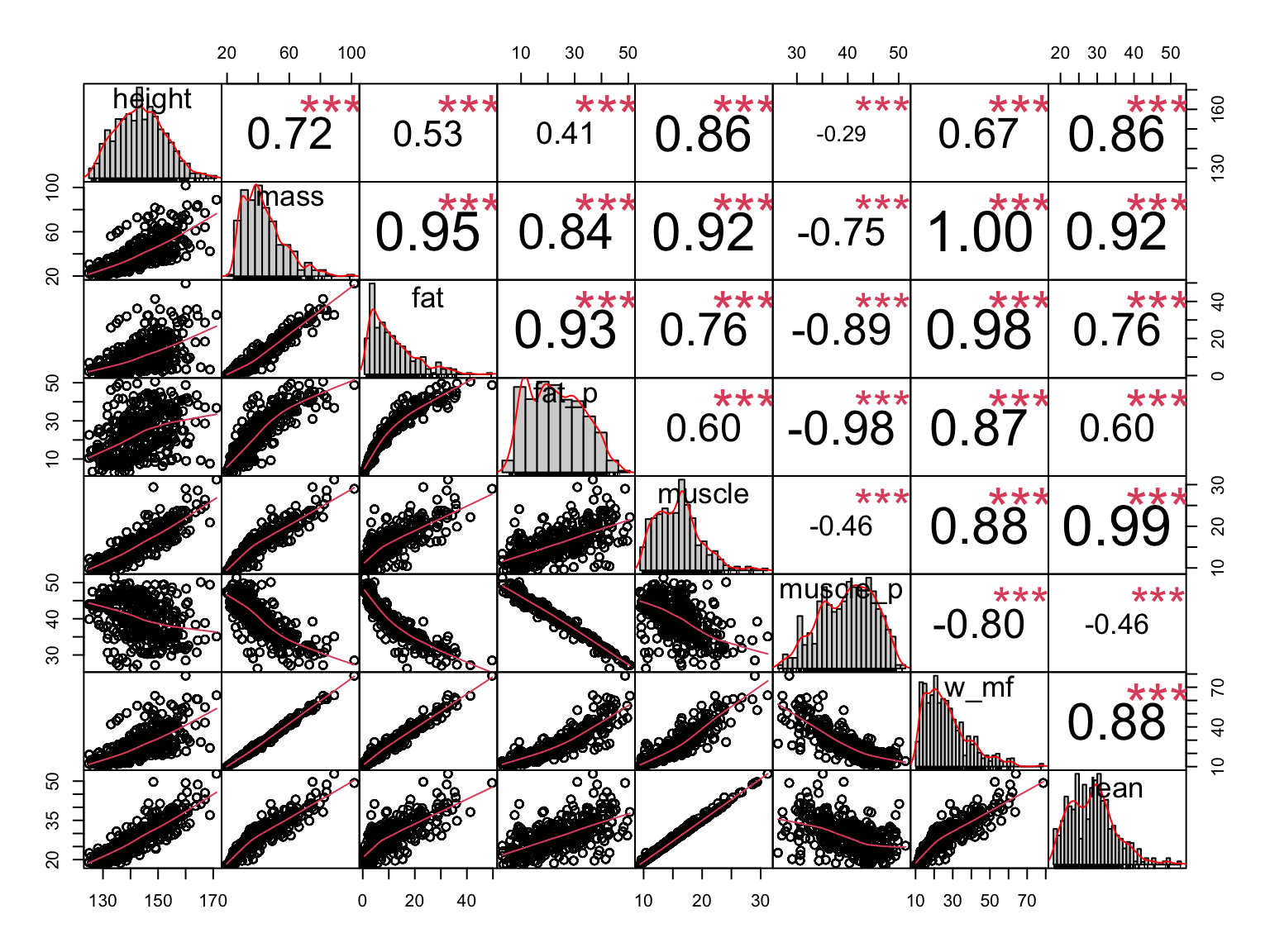
Correlations for anthropometric parameters assessed using the InBody; height = body height [cm], mass = body mass [kg], fat = body fat mass [kg], fat_p = body fat percent [%], muscle = body muscle mass [kg], muscle_p = body muscle mass percent [%], w_mf = sum of muscle mass and fat mass [kg], lean = body lean mass
m1 <-lmer(zScore ~0+ a1 + (1+ a1 | Child), data = dat_5, REML =FALSE, control =lmerControl(calc.derivs =FALSE))m1_0 <-update(m1, . ~+ Test + .)m1_m <-update(m1, . ~+ Test/( m) + .)m1_h <-update(m1, . ~+ Test/(h ) + .)m1_hm <-update(m1, . ~+ Test/(h + m) + .)
LRT 1 of fixed effects
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m1_0
10
4,233.194
4,287.987
-2,106.597
4,213.194
m1_m
15
3,644.544
3,726.734
-1,807.272
3,614.544
598.650
5
0
***
m1_hm
20
3,627.413
3,736.999
-1,793.706
3,587.413
27.131
5
0
***
m1_0
10
4,233.194
4,287.987
-2,106.597
4,213.194
m1_h
15
3,938.921
4,021.110
-1,954.460
3,908.921
304.274
5
0
***
m1_hm
20
3,627.413
3,736.999
-1,793.706
3,587.413
321.508
5
0
***
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
Including body mass and height into the model, nested within Test, improve the fit.
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRT revealed only significant quadratic effects for body mass improves models fit.
m3_hm1 <-update(m1, . ~+ Test/(h * m + m2) + .)m3_hm2 <-update(m1, . ~+ Test/(h * m + h * m2) + .)
Warning: Some predictor variables are on very different scales: consider
rescaling
LRT 3 of fixed effects
model
npar
AIC
BIC
logLik
deviance
Chisq
Df
p
sig
m2_m2
25
3,621.002
3,757.984
-1,785.501
3,571.002
m3_hm1
30
3,615.165
3,779.544
-1,777.582
3,555.165
15.837
5
0.007
**
m3_hm2
35
3,621.845
3,813.620
-1,775.922
3,551.845
3.320
5
0.651
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
Second-order interactions showed significant improvements in models fitted for interactions of body size with linear but not quadratic trends in body mass. Accordingly, m3_hm1 was reported in Section 4.2.
8.4.3 Means and standard deviations of model variables
Means and standard deviation of the model variables
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Warning in par(usr): argument 1 does not name a graphical parameter
Correlations for age-related parameters; a1 = age centered at 0 [years], m1 = maturity offset centered at 0 (Mirwald) [years], m2 = maturity offset centered at 0 (Moore) [years], m1pc1 = first principal component of age and maturity (Mirwald) [z-score], m1pc2 = second principal component of age and maturity (Mirwald) [z-score], m2pc1 = first principal component of age and maturity (Moore) [z-score], m2pc2 = second principal component of age and maturity (Moore) [z-score]
8.5.2 Model 1: Effect of maturity offset according to Mirwald, age, and gender on physical fitness
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRTs indicate that both principal components and gender improve the models fit.
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRTs reveal a significance third order interaction, however the model is very likely to be overparametrise according to AIC and BIC.
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
Both principal components entered into the random effect structure of Child did significantly improve the fit of the model. Accordingly, m3 will be reported in Section 5.3.
8.5.3 Model 2: Effect of maturity offset according to Moore, age, and gender on physical fitness
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRTs indicate that both principal components and gender improve the models fit.
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
LRTs reveal a significance third order interaction, however the model is very likely to be overparametrise according to AIC and BIC.
npar = number of parameters; AIC = Akaike information criterion; BIC = Bayesian information criterion; loglik; Chisp = chi square; DF = degrees of freedom
Both principal components entered into the random effect structure of Child did significantly improve the fit of the model. Accordingly, m6 will be reported in Section 5.4.
8.5.4 Means and standard deviations of model variables
Joining with `by = join_by(Child, Time)`
Joining with `by = join_by(Child, Time)`
Means and standard deviation of the model variables used in INT M1
physical fitness
Fühner, T., Granacher, U., Golle, K., & Kliegl, R. (2021). Age and sex effects in physical fitness components of 108,295 third graders including 515 primary schools and 9 cohorts. Scientific Reports, 11. https://doi.org/10.1038/s41598-021-97000-4
Fühner, T., Granacher, U., Golle, K., & Kliegl, R. (2022). Effect of timing of school enrollment on physical fitness in third graders. Nature - Scientific Reports, 12.
Mirwald, R. L., Baxter-Jones, A. D. G., Bailey, D. A., & Beunen, G. P. (2002). An assessment of maturity from anthropometric measurements. Medicine and Science in Sports and Exercise, 34, 689–694. https://doi.org/10.1249/00005768-200204000-00020
Moore, S. A., McKay, H. A., Macdonald, H., Nettlefold, L., Baxter-Jones, A. D. G., Cameron, N., & Brasher, P. M. A. (2015). Enhancing a somatic maturity prediction model. Medicine and Science in Sports and Exercise, 47. https://doi.org/10.1249/MSS.0000000000000588